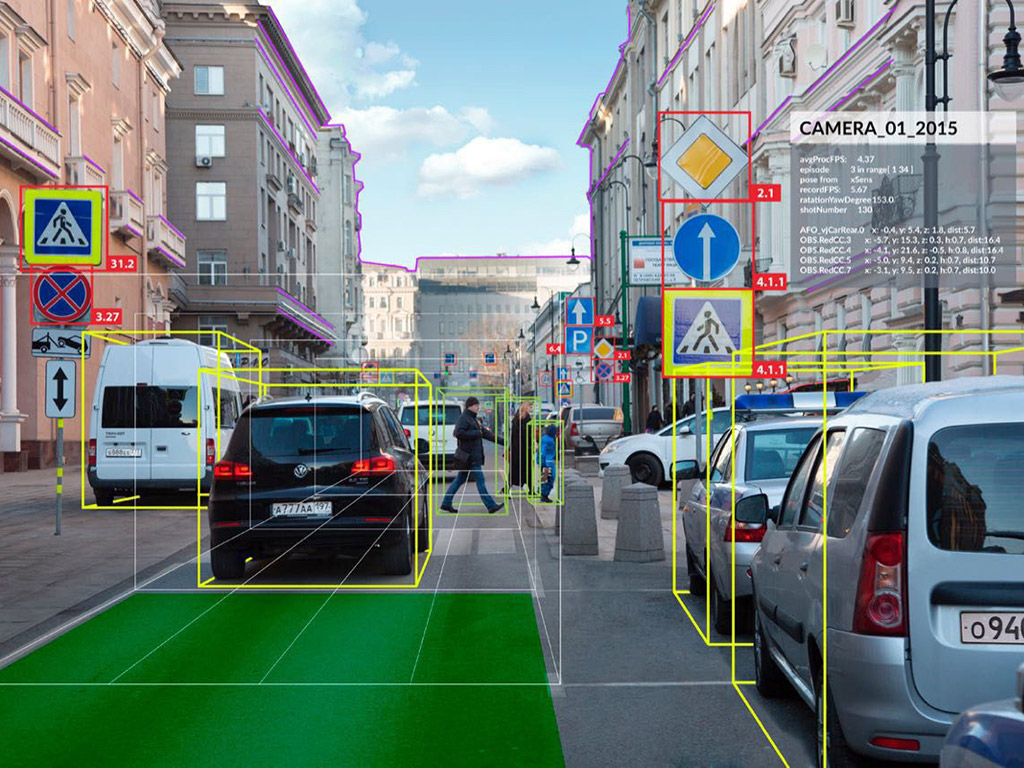
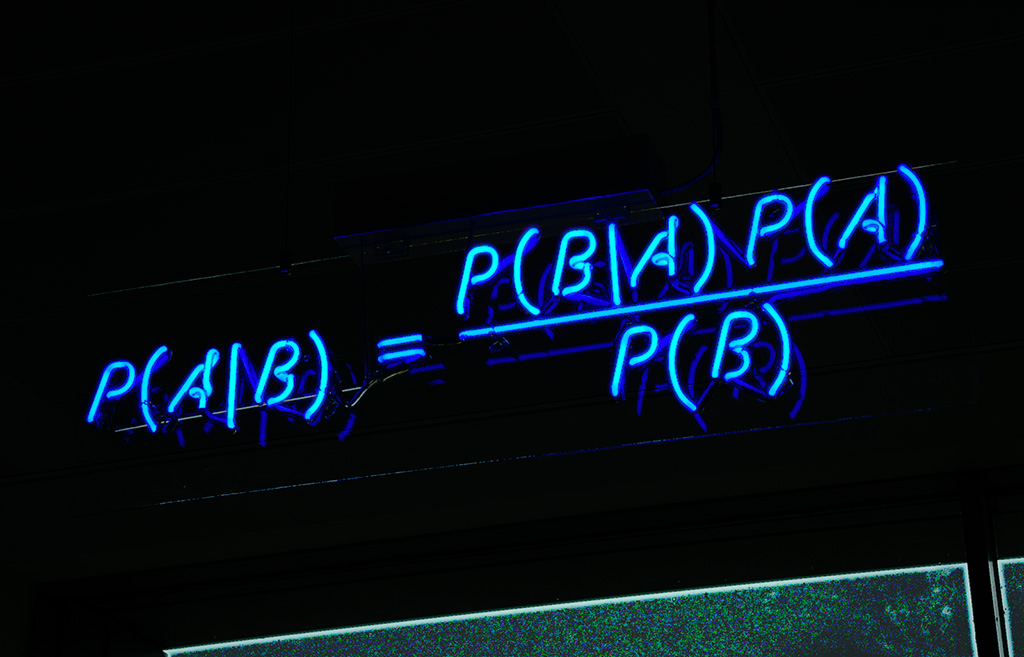La résolution de problèmes inverses permet de remonter à l’information originale d’un objet d’étude à partir d’observations dégradées de ce même objet. La généralité et la cohérence de l’approche inverse permet de traiter de façon globale et avec des méthodologies similaires des données de nature très différentes (images 2D ou 3D, images hyper-spectrales), voire hétérogènes.
En TSI, les applications phares de ce domaine d’étude sont la microscopie, l’astrophysique, ou l’imagerie médicale.
La première étape de résolution d’un problème inverse passe par l’écriture du problème direct dont la forme la plus simple s’écrit :
$$z = H(\overline{x}) + b$$ avec :
- \(\overline{x}\) : l’objet l’original;
- \(H\) : le modèle direct (linéaire ou non-linéaire) du dispositif d’acquisition;
- \(b\) : le bruit de mesure (dégradation stochastique), ici supposé additif;
- \(z\) : les observations.
Le problème inverse consiste alors à retrouver \(\overline{x}\) à partir de l’information contenue dans \(z\) et d’une information complète ou partielle de \(H\) et de la statistique de \(b\). Cette seule équation illustre de nombreux exemples telle que le débruitage (\(H\) est l’opérateur identité, \(z\) une version bruitée de l’objet original \(\overline{x}\)), la déconvolution (\(H\) est un opérateur de convolution, \(z\) une version floue de l’objet original \(\overline{x}\)), la séparation de sources (\(H\) est un opérateur de mélange, \(\overline{x}\) sont les sources originales et \(z\) les mélanges), ...
Les premiers travaux de cette discipline remontent à la définition du concept de problème bien posé proposé par J. Hadamard [1] en 1902 basé sur l’existence, l’unicité et la stabilité de la procédure d’inverson (estimation de \(\overline{x}\)). Par construction, la majorité des problèmes inverses considérés en TSI sont des problèmes bien posés. Lorsque \(H\) n’est pas inversible, de nombreux travaux ont alors porté sur la résolution par maximum de vraisemblance proposé par R.A. Fisher [2] en 1922 qui se ramène à la résolution des moindres carrés lorsque b est un bruit blanc Gaussien et à la pseudo-inverse de Moore-Penrose [3] si de plus H est linéaire. Depuis ces travaux fondateurs, les avancées majeures concernent la résolution des problèmes inverses par minimisation d’un critère de la forme :
$$ \widehat{x} \in \underset{x \in \Omega}{\mathrm{Argmin}} \;d(H(x);z) + \lambda r(x) $$ où \(\Omega\) représente l’ensemble des solutions acceptables, \(d(H(x),z)\) mesure une “distance” entre les observables \(z\) et leur modèle \(H(x)\), \(r(z)\) pénalise les solutions trop irrégulières et \(\lambda \geq 0\) est un hyper-paramètre de réglage. Cette minimisation générique permet de contrer le mauvais conditionnement des matrices (opérateurs) lorsque \(\lambda > 0\) et les solutions irrégulières obtenues par maximum de vraisemblance (qui se réduit au cas où \(\lambda = 0\)). Cette formulation peut être associée à un estimateur du maximum a posteriori, permettant d’interpréter \(d(H(x),z)\) comme un terme de vraisemblance et \(r(x)\) comme un terme d’a priori. Cette formulation est par excellence le moyen de prendre en compte la réalité du système de mesure avec ses limites (données incomplètes) ou ses imperfections mais aussi la statistique correcte du bruit. L’intérêt des approches de type problèmes inverses réside dans leur formulation générale qui les rend applicables à de nombreuses modalités et par leur capacité à fournir des estimateurs \(\widehat{x}\) ayant d’excellentes propriétés.
Les avancées majeures en problèmes inverses adaptent l’expression de \(d(⋅;⋅)\) et \(r(⋅)\) en fonction des avancées en optimisation numérique, elle sont donc indissociables des développements en optimisation impliquant des contraintes pouvant être non linéaires, non différentiables ou même non convexes, en très grande dimension – jusqu’à plusieurs milliards de paramètres. Voici les grandes classes d’approches :
- Régularisation de Tikhonov [4] proposée dans les années 60 aussi appelée régression d’arête et favorisant les solutions lisses ou filtrage de Wiener (1949) (requérant la connaissance de la densité spectrale du bruit et du signal) et également la pénalisation de Huber [5] indissociables de l’algorithme de gradient explicite et des versions accélérées (tels que l’algorithme de Levenberg-Marquardt ou L-BFGS) pour gérer la grande dimensionnalité.
- Dans les années 90, la régularisation par variation totale [6] favorisant les solutions constantes par morceaux et également dans les années 2000 la régularisation par a priori de parcimonie favorisant les solutions parcimonieuses dans des bases/trames d’ondelettes [7] pour lesquelles il a fallu attendre l’essor des méthodes proximales [8] (méthodes de sous-gradient implicite), pour être en mesure de traiter de grands volumes de données et d’obtenir des gains significatifs de qualité de reconstruction dans la résolution des problèmes inverses.
- Régularisation par apprentissage de dictionnaires [9] ou déconvolution aveugle indissociable des algorithmes de minimisation alternée et de l’optimisation non convexe.
Une autre contribution majeure de la discipline est attribuée à Candès-Romberg-Tao [10] concernant l’échantillonnage comprimé (2006), qui, sous condition d’aléa des coefficients de \(H\) et d’a priori de parcimonie dans l’objet d’intérêt, permet d’avoir des garanties de reconstruction exacte du support de l’objet original. L’échantillonnage comprimé permet alors de guider le design du dispositif d’acquisition des données pour en améliorer les performances de reconstruction et réduire significativement les temps d’acquisition.
Une question sensible dans la résolution des problèmes inverses concerne le choix de l’hyperparamètre \(\lambda\). Les principales techniques proposées pour régler automatiquement ce paramètre sont la minimisation d’estimateurs de l’erreur quadratique moyenne (estimateur non-biaisé du risque de Stein [SURE, 12] ou validation croisée généralisée [GCV, 13]), la courbe en L [14], ou des approches bayésiennes (marginalisation du la distribution a posteriori ou Monte-Carlo Markov chain [MCMC] ces dernières nécessitant de spécifier la densité de probabilité de \(\lambda\)).
Références
[1] J. Hadamard, “Sur les problèmes aux dérivées partielles et leur signification physique”, Princeton
University Bulletin, p. 49-52 (1902).
[2] R. Fisher, “On the mathematical foundations of theoretical statistics”, Philos. Trans. Roy. Soc. London Ser.
A, (1922).
[3] R. Penrose, “A generalized inverse for matrices”, Proceedings of the Cambridge Philosophical Society, vol.
51, p. 406-413 (1955).
[4] A.N. Tikhonov, “Solution of incorrectly formulated problems and the regularization method”, Soviet Math Dokl
4, 1035-1038 English translation of Dokl Akad Nauk SSSR 151, 501-504 (1963).
[5] P.J. Huber, “Robust Estimation of a Location Parameter”, Annals of Statistics, 53 (1): 73-101 (1963).
[6] L.I. Rudin, S. Osher & E. Fatemi, “Nonlinear total variation based noise removal algorithms”, Physica D:
Nonlinear Phenomena, no 60.1, p. 259-268 (1992).
[7] I. Daubechies, M. Defrise & C. De Mol, “An iterative thresholding algorithm for linear inverse problems with
a sparsity constraint”, Communications on Pure and Applied Mathematics, Vol. LVII, 1413-145, (2004).
[8] H.H. Bauschke & P.L. Combettes, “Convex analysis and monotone operator theory in Hilbert spaces”, Springer
Science (2011).
[9] J. Mairal, G. Sapiro & M. Elad, “Learning Multiscale Sparse Representations for Image and Video
Restoration”, Multiscale Modeling & Simulation. 7 (1): 214-241, (2008).
[10] E. Candès, J. Romberg & T. Tao, “Stable signal recovery from incomplete and inaccurate measurements”,
Communications on Pure and Applied Mathematics. 59 (8): 1207-1223, (2006).
[11] M. Pereyra, P. Schniter, E. Chouzenoux, J.C. Pesquet & J.Y. Tourneret, “A survey of stochastic simulation
and optimization methods in signal processing”, IEEE Journal of Selected Topics in Signal Processing 10 (2),
224-241, (2015).
[12] C.M. Stein, “Estimation of the Mean of a Multivariate Normal Distribution”, in The Annals of Statistics,
Institute of Mathematical Statistics, Vol. 9, pp. 1135–1151 (1981).
[13] G.H. Golub, M. Heath & G. Wahba, “Generalized cross-validation as a method for choosing a good ridge
parameter” Technometrics, Vol. 21, pp. 215–223 (1979).
[14] P.C. Hansen, “Analysis of discrete ill-posed problems by means of the L-curve”, SIAM Review, Vol. 34, pp.
561–580 (1992).